Table of Contents
- Argument philosophy
- Interpretation process
- java.io.File (file or directory)
- java.io.File (directory)
- java.net.URL
- FutureEntity
- NamedReadableFile
- ReadableFile
- Existing WritableFile
- New WritableFile
- RandomlyAccessibleFile
- Read only entity holder
- Read only Entity (file or directory)
- Read only Directory
- Read/write Directory
- Read/write Entity (file or directory)
- Read/write EFile
- XML Source
- ReadableFile implementations
- NamedReadableFile implementations
- WritableFile implementations
- RandomlyAccessibleFile implementations
- EntityView implementations
- FutureEntityStrategy implementations
Argument interpretation gives great flexibility in which kinds of arguments that can be used for setting task properties. Most tasks use ArgumentInterpreter together with an ArgumentInterpretationStrategy to interpret some of their properties. This appendix describes how the different strategies interpret properties into the expected types. It also lists useful implementations of the different argument types.
Tasks are implemented to use the simplest types of arguments possible. If a task needs a container for reading data from, it uses a ReadableFile. If it wants the container to have a name, it uses a NamedReadableFile, and so on.
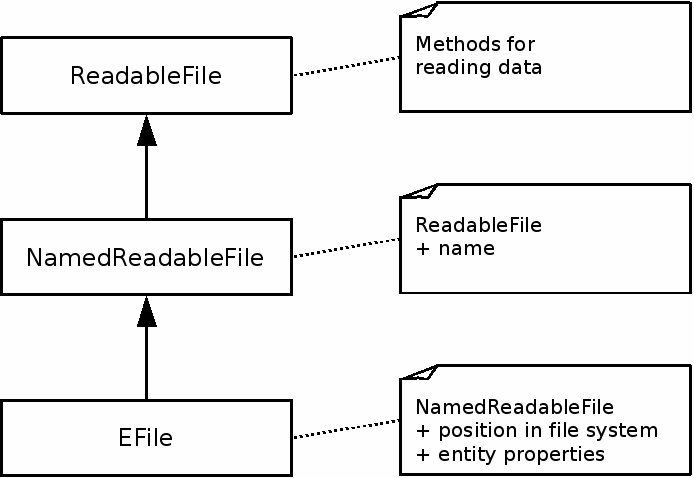
Simple argument types, such as ReadableFile, come with many implementations. Some of ReadableFile's implementations are UrlReadableFile, CharSequenceReadableFile and EFile. A ReadableFile can always be turned into a NamedReadableFile by wrapping it in a NamedReadableFileAdapter. For more information, see the implementation sections below and Appendix B, EntityFS cookbook.
Unless a custom interpretation method or class is used, arguments are interpreted using the ArgumentInterpreter.interpret(Object, org.schmant.arg.ArgumentIntepretationStrategy) method. The first argument to that method is one object or an array or collection of objects. These objects are the objects to interpret. The second argument to the method is the ArgumentInterpretationStrategy to use
First the interpret method flattens the object collection (using FlatteningList), and all closures in the collection are run. Then the produced objects are fetched from all Producer:s in the collection. The resulting argument list is fed into the ArgumentInterpretationStrategy object, which interprets the list using its strategy and returns an ArgumentInterpretationResult object containing all interpreted objects and the objects that it was not able to interpret.
When it is created, the ArgumentInterpretationStrategy object can be configured to treat different situations as errors or not. If it encounters a situation that it has been configured to treat as an error it will throw an ArgumentInterpretationException. These two configuration modes are supported by all strategy objects:
- ArgumentInterpretationStrategy.ALLOW_NOT_INTERPRETED
Tell the strategy object that it is not an error if it cannot interpret all objects. All objects that it cannot interpret along with their interpretation traces that describes how the strategy tried to interpret them are returned in the ArgumentInterpretationResult object.
- ArgumentInterpretationStrategy.ALLOW_ONE_AND_ONLY_ONE_RESULT_OBJECT
Allow only one result object. If the argument list is interpreted into more than one object, this results in an error.
The following sections describe how the different ArgumentInterpretationStrategy objects interpret objects into different types.
InterpretAsFileStrategy is used to interpret objects into File:s (files and/or directories).
java.io.File are used by tasks that use
modules that are not EntityFS-aware, i.e. mostly tasks that run external programs.
The files returned by the interpretation methods may or may not exist. Their
paths may be relative or absolute.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.1. Interpretation of an argument into a file or directory java.io.File
| # | Type of input | Algorithm |
|---|---|---|
| 1. | File | Return it. |
| 2. | CharSequence (a String, for instance) | The text is interpreted as a path name. A new File object is created with the path name and returned. |
| 3. | EntityView that supports the ECFileResolvable capability. | Return the Entity's backing File. |
| 4. | DirectoryRepresentation whose directory supports the ECFileResolvable capability. | Return the directory's backing File. |
| 4. | NamedReadableFile | The contents of the file is copied to a temporary file with the same name. The File object referencing the temporary file is returned. |
| 5. | ReadableFile | The contents of the file is copied to a temporary file with a generated name. |
| 6. | FutureEntity (existing) | Return the File that backs the entity. This requires that the entity supports the ECFileResolvable capability. |
| 7. | FutureEntity (nonexisting) | Return a File representing the future entity's location, based on the location of its base directory. This requires that the base directory supports the ECFileResolvable capability. |
InterpretAsFileDirectoryStrategy is used to interpret objects into directory File:s.
This method uses the results from a InterpretAsFileStrategy object, but throws an ArgumentInterpretationException if the result is not a directory.
InterpretAsUrlStrategy is used to interpret objects into URL objects.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.2. Interpretation of an argument into a java.net.URL
| # | Type of input | Algorithm |
|---|---|---|
| 1. | URL | Return it. |
| 2. | URI | Call toUrl() on it and return the result.
If toUrl() throws an
MalformedURLException, rethrow it as an
ArgumentInterpretationException. |
| 3. | CharSequence (a String, for instance) | Try to create an URL object from the text. If that results in a MalformedURLException, try to create a File from the text and convert it to an URL. |
| 4. | File | Convert it to an URL and return it. |
| 5. | EntityView that supports the ECFileResolvable capability. | Return a URL referencing the EntityView's backing File. |
| 6. | DirectoryRepresentation whose directory supports the ECFileResolvable capability. | Return a URL referencing the directory's backing File. |
| 7. | NamedReadableFile | The contents of the file is copied to a temporary file with the same name. A URL that points to the file is returned. |
| 8. | ReadableFile | The contents of the file is copied to a temporary file with a generated name. A URL that points to the file is returned. |
| 9. | FutureEntity (existing) | Create a URL that references the File that backs the entity. This requires that the entity supports the ECFileResolvable capability. |
| 10. | FutureEntity (nonexisting) | Return a URL representing the future entity's location, based on the location of its base directory. This requires that the base directory supports the ECFileResolvable capability. |
InterpretAsFutureEntityStrategy is used to interpret objects into FutureEntity objects.
The InterpretAsFutureEntityStrategy constructor takes an optional
source value. It can be used as a hint to a
FutureEntityStrategy object to help it decide what to call the
entity it creates. It is up to each task that use future entities to decide if
it should provide a hint. A process task uses the
source property as a hint.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.3. Interpretation of an argument into a FutureEntity
| # | Type of input | Algorithm |
|---|---|---|
| 1. | FutureEntity | Return it. |
| 2. | FutureEntityStrategy | Use the strategy and the supplied hint (see above) to create a FutureEntity. If no hint was supplied, the method throws an ArgumentInterpretationException. |
| 3. | File | If the file exists, create a FutureEntity representing it. If not, create a FutureEntity based on the nearest existing parent directory and the remaining path down to the referenced (future) entity. |
| 4. | EntityView | Return a FutureEntity representing the existing entity. |
| 5. | DirectoryRepresentation | Return the directory. |
InterpretAsNamedReadableFileStrategy is used to interpret objects into NamedReadableFile:s.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.4. Interpretation of an argument into a NamedReadableFile
| # | Type of input | Algorithm |
|---|---|---|
| 1. | NamedReadableFile | Return it. |
| 2. | RenamedFile | Run the file property through the
getReadableFile method. Return a
NamedReadableFileAdapter created using the result from the
method and the value of the name property. |
| 3. | File | If the file object references an existing file, return a NamedReadableFileAdapter that wraps the file object. Otherwise, the File object cannot be interpreted. |
| 4. | CharSequence (a String, for instance) | Interpret the supplied text as an URI. If the URI is absolute, return a UrlReadableFile wrapped in a NamedReadableFileAdapter. (This means that any valid URI can be used as a file.) If the URI is relative, and thus a local file system path, and it references an existing file, return a NamedReadableFile object representing the file. If the relative URI references a nonexisting file, it cannot be interpreted. |
| 5. | FutureEntity | If the future entity object references an existing NamedReadableFile, return it. If not, the FutureEntity cannot be interpreted. |
See CopyTF examples for how to use an URL as a NamedReadableFile.
InterpretAsReadableFileStrategy is used to interpret objects into ReadableFile objects.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.5. Interpretation of an argument into a ReadableFile
| # | Type of input | Algorithm |
|---|---|---|
| 1. | ReadableFile | Return it. |
| 2. | byte[] | The array is wrapped in a ByteArrayReadableFile and returned. |
| 3. | RenamedFile | Run the file property through the
getReadableFile method. Return a
NamedReadableFileAdapter created using the result from the
method and the value of the name property. |
| 4. | File | If the file object references an existing file, return a FileReadableFile that wraps the file object. Otherwise, the File cannot be interpreted. |
| 5. | CharSequence (a String, for instance) | Interpret the supplied text as an URI. If the URI is absolute, return a UrlReadableFile wrapped in a NamedReadableFileAdapter. This means that any valid URI can be used as a file. If the URI is relative, and thus a local file system path, and it references an existing file, return a NamedReadableFile object representing the file. If the relative URI references a nonexisting file, it cannot be interpreted. |
| 6. | FutureEntity | If the future entity object references an existing NamedReadableFile, return it. If not, it cannot be interpreted. |
See CopyTF examples for how to use an URL as a ReadableFile.
InterpretAsWritableFileStrategy is used to interpret objects into WritableFile objects representing existing files.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.6. Interpretation of an argument into an existing WritableFile
| # | Type of input | Algorithm |
|---|---|---|
| 1. | WritableFile | Return it. |
| 2. | FutureEntity | Get the file referenced by the future entity, possibly creating it if it does not already exist. |
| 3. | File | If the file does not exist, create it. Return the file wrapped in a ReadWritableFileAdapter. |
The InterpretAsNewWritableFileStrategy interprets an object into a location for a new writable file, creates the file and then returns it. If there already is a file at the target location, it uses an OverwriteStrategy to decide what to do with it. If the strategy decides to keep the old file, most tasks will fail.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.7. Interpretation of an argument into a new WritableFile
| # | Type of input | Algorithm |
|---|---|---|
| 1. | WritableFile | Return it. |
| 2. | FutureEntity | If there already is an entity at the location referenced by the future entity, use the overwrite strategy to try to delete it. If successful, create a new file and return it. |
| 3. | NewWritableFile | Return the new writable file. |
| 4. | File | If there already is an entity at the location referenced by the file object, use the overwrite strategy to try to delete it. If successful, create a new file and return it. |
InterpretAsRandomlyAccessibleFileStrategy is used to interpret objects into RandomlyAccessibleFile:s.
For some valid arguments, the returned file may be read only.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.8. Interpretation of an argument into a RandomlyAccessibleFile
| # | Type of input | Algorithm |
|---|---|---|
| 1. | RandomlyAccessibleFile | Return it. |
| 2. | FutureEntity | If the future entity object references an existing RandomlyAccessibleFile, return it. If not, the object cannot be interpreted. |
| 3. | File | Wrap the file in a ReadWritableFileAdapter and return it. |
| 4. | byte[] | Wrap the byte array in a ByteArrayReadableFile object and return it. |
| 5. | CharSequence (a String for instance) | Create an URI from the string. If the URI references a local file, return it. Otherwise, the object cannot be interpreted. |
InterpretAsEntityHolderStrategy is used to interpret objects into EntityHolder objects.
An entity holder is a very limited Directory.
The returned directory is
wrapped in a DirectoryRepresentation object. It contains a
DirectoryView and an optional EntityFilter. If the
filter is set, the running task will only see the entities matching the
filter. If the task is recursive, it will still propagate down into all
subdirectories, even if they don't match the filter. This is how
using a DirectoryRepresentation source
differs from using a DirectoryView source; when using a
DirectoryView source, only the subdirectories matching the filter will be
processed.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.9. Interpretation of an argument into an entity holder
| # | Type of input | Algorithm |
|---|---|---|
| 1. | EntityHolder | Return it. |
| 2. | DirectoryRepresentation | Return the directory. |
| 3. | DirectoryAndFilter | Run the directory property through
the getReadOnlyDirectory method.
Combine it with the supplied filter into a DirectoryRepresentation
and return it. |
| 4. | DirectoryView | Return it in a DirectoryRepresentation. |
| 5. | FutureEntity | If the future entity references an existing DirectoryView (or any subclass), wrap the directory in a DirectoryRepresentation and return it. Otherwise, the object cannot be interpreted. |
| 6. | CharSequence (a String, for instance) | Interpret the text as a file path. If it references an existing directory, return the directory wrapped in a DirectoryRepresentation. Otherwise, the object cannot be interpreted. |
| 7. | File | If the File object references an existing directory, create a temporary entity object based on the entity and return it. If not, the object cannot be interpreted. |
InterpretAsReadOnlyEntityStrategy is used to interpret objects as read only EntityView:s.
By calling this method, the client says that it does not require a entity that it can write to, only one it can read from. The returned entity is not required to be read only, it might just as well be read/write.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.10. Interpretation of an argument into a read only EntityView
| # | Type of input | Algorithm |
|---|---|---|
| 1. | EntityView | Return it. |
| 2. | DirectoryRepresentation | Return the directory. |
| 3. | FutureEntity | If the future entity references an existing entity, return it. Otherwise, the object cannot be interpreted. |
| 4. | NamedReadableFile | Create a new file with the same name in a temporary directory. Copy the contents of the supplied file to the new file and return it. |
| 5. | ReadableFile | Create a new temporary file with a generated name and copy the contents of the supplied file to it. Return the temporary file. |
| 6. | CharSequence (a String, for instance) | Interpret the text as a file system path. If it references an existing entity (file or directory), create a temporary entity object based on the entity and return it. If not, the object cannot be interpreted. |
| 7. | File | If the File object references an existing entity (file or directory), create a temporary entity object based on the entity and return it. If not, the object cannot be interpreted. |
InterpretAsReadOnlyDirectoryStrategy is used to interpret objects as read only DirectoryView:s.
By calling this method, the client says that it does not require a directory that it can write to, only one it can read from. The returned directory is not required to be read only, it might just as well be read/write.
The returned directory is
wrapped in a DirectoryRepresentation object. It contains a
DirectoryView and an optional EntityFilter. If the
filter is set, the running task will only see the entities matching the
filter. If the task is recursive, it will still propagate down into all
subdirectories, even if they don't match the filter. This is how
using a DirectoryRepresentation source
differs from using a DirectoryView source; when using a
DirectoryView source, only the subdirectories matching the filter will be
processed.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.11. Interpretation of an argument into a read only Directory
| # | Type of input | Algorithm |
|---|---|---|
| 1. | DirectoryRepresentation | Return it. |
| 2. | DirectoryAndFilter | Call this method with the DirectoryAndFilter's directory to get the directory. Return the directory and the filter in a DirectoryRepresentation object. |
| 3. | FutureEntity | If the future entity references an existing DirectoryView (or any subclass), return it. Otherwise, the object cannot be interpreted. |
| 4. | CharSequence (a String, for instance) | Interpret the text as a file path. If it references an existing directory, return the directory wrapped in a DirectoryRepresentation. Otherwise, the object cannot be interpreted. |
| 5. | File | If the File object references an existing directory, create a temporary entity object based on the entity and return it. If not, the object cannot be interpreted. |
InterpretAsDirectoryStrategy is used to interpret objects as read/write DirectoryView:s.
The returned directory is
wrapped in a DirectoryRepresentation object. It contains a
DirectoryView and an optional EntityFilter. If the
filter is set, the running task will only see the entities matching the
filter. If the task is recursive, it will still propagate down into all
subdirectories, even if they don't match the filter. This is how
using a DirectoryRepresentation source
differs from using a DirectoryView source; when using a
DirectoryView source, only the subdirectories matching the filter will be
processed.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.12. Interpretation of an argument into a read/write Directory
| # | Type of input | Algorithm |
|---|---|---|
| 1. | DirectoryRepresentation | Return it. |
| 2. | DirectoryAndFilter | Run the directory property through
the getReadWriteDirectory method.
Combine it with the supplied filter into a DirectoryRepresentation
and return it. |
| 3. | DirectoryView | Return it in a DirectoryRepresentation with no filter. |
| 4. | FutureEntity | If the future entity references an existing DirectoryView (or any subclass), wrap the directory in a DirectoryRepresentation and return it. Otherwise, the object cannot be interpreted. |
| 5. | CharSequence (a String, for instance) | Interpret the text as a file system path. If it references an existing directory, return the directory wrapped in a DirectoryRepresentation. Otherwise, the object cannot be interpreted. |
InterpretAsEntityStrategy is used to interpret objects as read/write EntityView:s.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.13. Interpretation of an argument into a read/write Entity
| # | Type of input | Algorithm |
|---|---|---|
| 1. | EntityView | Return it. |
| 2. | DirectoryRepresentation | Return the representation's directory. |
| 3. | FutureEntity | If the future entity references an existing entity, return it. Otherwise, the object cannot be interpreted. |
| 4. | CharSequence (a String, for instance) | Interpret the text as a file system path. If it references an existing entity (file or directory), create a temporary entity object based on the entity and return it. If not, the object cannot be interpreted. |
| 5. | File | If the File object references an existing entity (file or directory), create a temporary entity object based on the entity and return it. If not, the object cannot be interpreted. |
InterpretAsEFileStrategy is used to interpret objects as read/write EFile:s.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.14. Interpretation of an argument into a read/write EFile
| # | Type of input | Algorithm |
|---|---|---|
| 1. | EFile | Return it. |
| 2. | FutureEntity | If the future entity references an existing EFile, return it. Otherwise, the object cannot be interpreted. |
| 3. | CharSequence (a String, for instance) | Interpret the text as a file system path. If that path does not reference an existing file, treat the text as an URI. If an existing file was referenced by the text, create a temporary file entity object based on the file and return it. If not, the object cannot be interpreted. |
| 4. | File | If the File object references an existing file, create a temporary EFile object based on the File and return it. If not, the object cannot be interpreted. |
InterpretAsXmlSourceStrategy is used to interpret objects as XML Source objects that can be used for XSL transformations.
First, ArgumentInterpreter preprocesses the argument list as described above. Then the strategy object tries to interpret each object in the preprocessed list by checking if each object is of any of the types listed below, in the order that they are listed. If it is, the algorithm listed at the matched type is used to create the object tor return. If there are objects for which there are no matches, the configuration of the ArgumentInterpretationStrategy decides what will happen.
Table A.15. Interpretation of an argument into an XML Source
| # | Type of input | Algorithm |
|---|---|---|
| 1. | Source | Return it. |
| 2. | Document | Create a DOMSource object and return it. |
| 3. | Anything that can be interpreted by InterpretAsReadableFileStrategy. | Open the file and create a StreamSource object and return it. |
A ReadableFile is a container for file data. It can be opened and read from any number of times.
The tree view below lists the type's inheritance hierarchy. The names of interfaces are written in italics.
ReadableFile -- container for file data that can be opened and read from + ByteArrayReadableFile -- file that reads data from a byte array + CharSequenceReadableFile -- file that reads data from a CharSequence | (a String, for instance) + BZip2ReadableFile -- file that transparently decompresses data when read. + GZipReadableFile -- file that transparently decompresses data when read. + GZipReadableFileProxy -- file that transparently decompresses data when read. + LzmaReadableFile -- file that transparently decompresses data when read. + NamedReadableFile -- a ReadableFile with a name + ReadWritableFile -- a read/write file | + ReadWritableFileAdapter -- Adapter from a File to a ReadWritableFile | + EFile -- a file entity + ManualNamedReadableFile -- named file that reads data from a byte array | or a CharSequence (such as a String) + NamedReadableFileAdapter -- adapter for turning a ReadableFile | into a NamedReadableFile + ReadWritableFileAdapter -- adapter for turning a File into a | NamedReadableFile + UrlReadableFile -- named file that reads data from the target of a URL
Since ReadableFile is a very small interface, it is easy to do a custom implementation of it if none of the already existing implementations suffice.
A NamedReadableFile is a ReadableFile with a name. Any ReadableFile can be adapted to a NamedReadableFile by using the NamedReadableFileAdapter.
The tree view below lists the type's inheritance hierarchy. The names of interfaces are written in italics.
NamedReadableFile -- a ReadableFile with a name + ReadWritableFile -- a read/write file | + ReadWritableFileAdapter -- Adapter from a File to a ReadWritableFile | + EFile -- a file entity + ManualNamedReadableFile -- named file that reads data from a byte array | or a CharSequence (such as a String) + NamedReadableFileAdapter -- adapter for turning a ReadableFile | into a NamedReadableFile + ReadWritableFileAdapter -- adapter for turning a File into a | NamedReadableFile + UrlReadableFile -- named file that reads data from the target of a URL
Since NamedReadableFile is a very small interface, it is easy to do a custom implementation of it if none of the already existing implementations suffice.
A WritableFile is a sink for data. It can be opened for writing to or appending to any number of times.
WritableFile -- container for file data that can be opened and written to + BZip2ExistingWritableFileProxy -- file that transparently compresses data written to it. + BZip2NewWritableFileProxy -- file that transparently compresses data written to it. + BZip2WritableFile -- file that transparently compresses data written to it. + FileWritableFile -- adapter from a File to a WritableFile + GZipExistingWritableFileProxy -- file that transparently compresses data written to it. + GZipNewWritableFileProxy -- file that transparently compresses data written to it. + GZipWritableFile -- file that transparently compresses data written to it. + LzmaExistingWritableFileProxy -- file that transparently compresses data written to it. + LzmaNewWritableFileProxy -- file that transparently compresses data written to it. + LzmaWritableFile -- file that transparently compresses data written to it. + MultiplexingExistingWritableFileProxy -- file that writes to one or more proxied files. + MultiplexingNewWritableFileProxy -- file that writes to one or more proxied files. + ReadWritableFile -- a read/write file + ReadWritableFileAdapter -- Adapter from a File to a ReadWritableFile + EFile -- a file entity
Since WritableFile is a very small interface, it is easy to do a custom implementation of it if none of the already existing implementations suffice.
A RandomlyAccessibleFile is a data container that may a client may open for random access. It may be read/write or it may be read only.
RandomlyAccessibleFile -- container for file data that can be opened for random access + ByteArrayReadableFile -- Read only container for bytes. + ReadWritableFile -- a read/write file + ReadWritableFileAdapter -- Adapter from a File to a ReadWritableFile + EFile -- a file entity
An EntityView is a file system entity, either a file or a directory. It has a unique location in a FileSystem.
The tree view below lists the type's inheritance hierarchy. The names of interfaces are written in italics.
EntityView -- view of generic file system entity + Entity -- generic file system entity | + EFile -- file entity | + Directory -- directory entity (no filters) + DirectoryView -- Directory with contents filtered by zero or more | EntityFilter:s + Directory -- directory entity (no filters)
The FutureEntityStrategy defines a strategy that uses a source object and creates a FutureEntity from it. Note that you can use a closure instead of a future entity strategy.
The tree view below lists the type's inheritance hierarchy. The names of interfaces are written in italics.
FutureEntityStrategy -- future entity strategy + FutureEntityIndexStrategy -- strategy that creates future entities on the form [base_directory]/[prefix][index][suffix] where index is incremented for each created future entity